Mortgage Data Analysis
I. Introduction
Mortgage default occurs when a borrower fails to make a repayment to the lender. This project analyzes the characterics of borrowers and loans that would later default using the data available at origination. Being able to flag a bad loan before making a funding decision is an ideal scenario for both the lenders and borrowers. The lenders would be more careful about funding that loan, while the borrowers, if rejected, are not taking more debt than they can repay. Therefore, being able to flag a loan at the origination state is very important.
II. Data
1. Data Source
This project uses Freddie Mac Single Family Loan Level Data and performs analysis on all loans funded by Freddie Mac between 2013 and 2018. The data was obtained from Freddie Mac website in as zip files. Every zip file contains data of the entire year which was broken down into data of each quarter. Each quarter contains two different text files: (1) Origination Data and (2) Performance Data. The structure of the data is as follow:
- historical_data_200X.zip
- historical_data1_Q1200X.zip
- historical_data1_Q2200X.zip
- historical_data1_Q3200X.zip
- historical_data1_Q4200X.zip
- historical_data1_Q1200X.txt (Origination Data)
- historical_data1_time_Q1200X.txt (Performance Data)
The Origination data contains variables that indicate the characteristics of the borrowers, the loans, and the properties. More specifically:
- Borrower characteristics: Credit Score, First Time Homebuyer, Debt-to-Income (DTI), Total number of Borrowers
- Loans characteristics: Date of First Payment, Maturity Date, Mortgage Insurance (MI) Percentage, Combined Loan-to-Value, Loan-to-Value (LTV), Interest Rate, Channel, Loan Purpose, Term, Seller, Servicer, Conformity Flag, Unpaid Principal Balance, Quarter and Year when the loan was funded
- Property characteristics: Metropolitan Statistical Areas (MSA) , Unit, Occupancy Status, Property State, Property Type, Postal Code
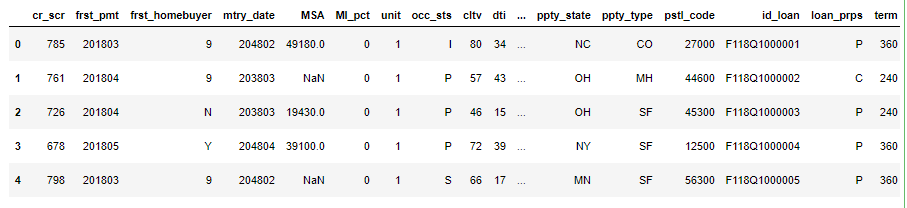
The Performance data contains information on how the loans perform monthly. It contains variable such as Current Unpaid Principal Balance, Loan Status, Loan Age, Number of Years to Maturity, etc. For the purpose of this study, only variable Loan Status from Performance data was used.
The 30-year fixed mortgage interest rate downloaded from Freddie Mac website contains the monthly interest rate for 30-year fix-rate mortgages between 2013 and 2018. This variable was later used in calculating the rate of Spread at Origination (SATO).
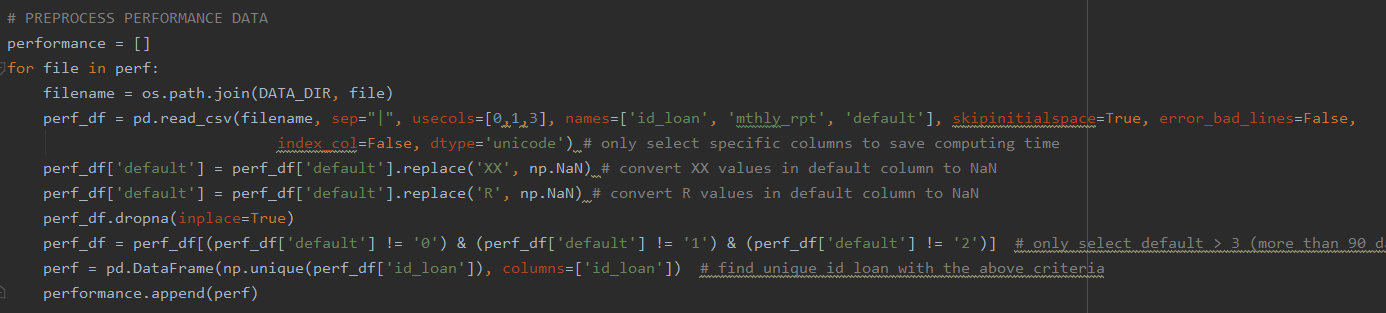
2. Data Preprocessing
- Extract zip files into text files
- Import all origination files, concatenate them into one dataframe, and replace placeholder values with NaN
- Select loans that delinquent for more than 90 days from performance data
- Merge unique loan ids from performance data to orignation data
- Remove all NaN values
- Calculate the average interest rate for every quarter using Excel
- Merge the quarterly interest rate to the master dataframe
- Calculate the Spread at Orgination (SATO) rate SATO (%) = Average Fixed Rate - Stated Interest Rate
The code below is a snipet of the data cleaning process.
III. Exploratory Data Analysis
1. Geographical Distribution
Tab Overview shows the total number of loans funded in each state. Click on any state in the first plot to see the corresponding total by year in the second plot.
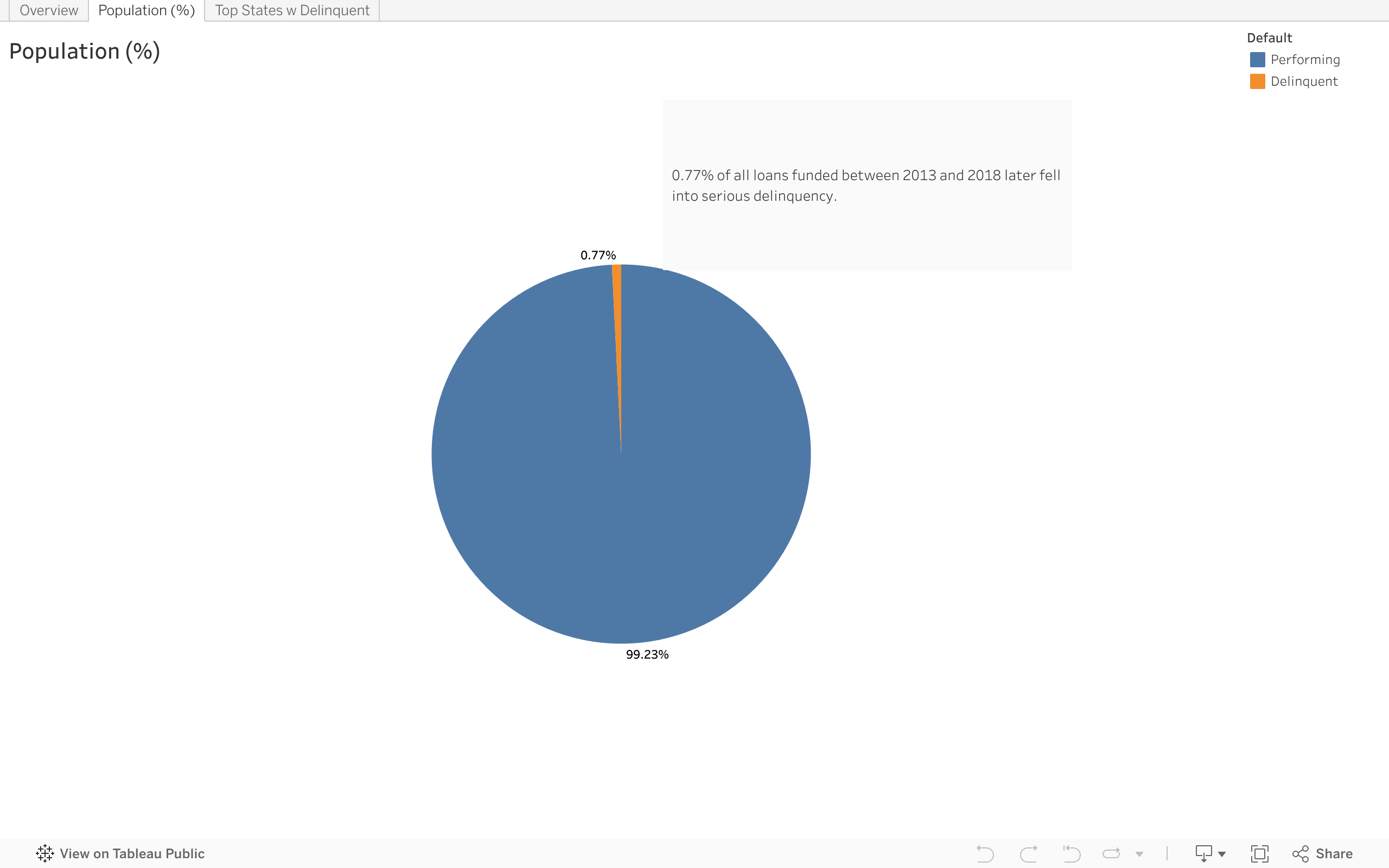
Tab Population (%) compares the number of loans in serious delinquency vs performing loans.
Tab Top States with Delinquency shows the top 5 states with the highest rate of delinquency.
During the 2013-2018 period, Freddie Mac purchased the most properties in California, Texas, Florida, and Ohio. These states were also the ones with the highest delinquency rates. The total number of delinquency in these states made up about 50% of all delinquency in the US.
2. Borrowers and Loans' Characteristics
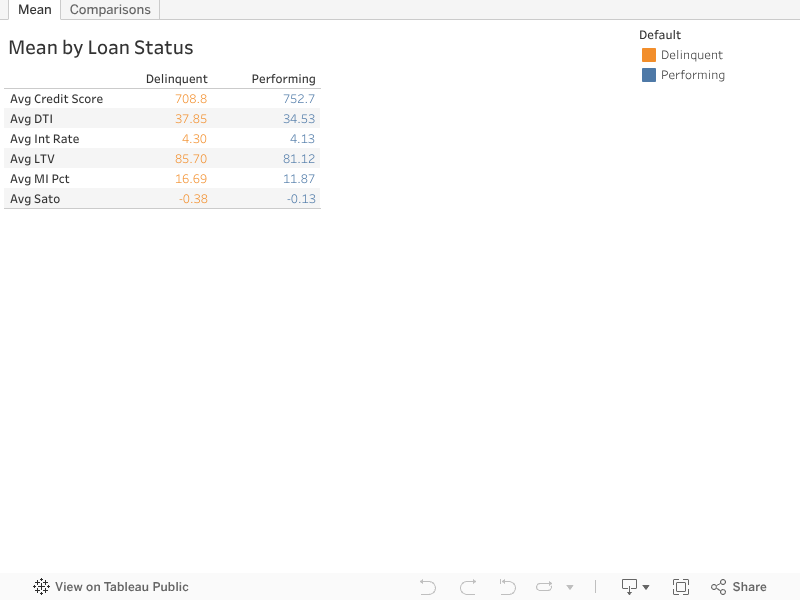
The plots above calculate the average of each numberical characteristics and compare between performning loans and delinquent loans. Overall, average DTI, LTV, MI percentage, and interest rate of default loans are higher than performing loans. Average credit score and SATO rate of delinquent loans are higher than performing loans. The wide gap in SATO rate between these loan statuses indicates on average, both perfoming loans and delinquent loans received higher interest rates than market average. Additionally, loans that would later delinquent received a much higher interest rates at origination than loans that would later perform.
IV. Modeling
Before modeling, One Hot Encoder was applied to categorical values and Label Encoder was applied to the target. The data was standardized and split into training and testing sets with the ratio of 7:3. The dataset was resampled twice to compare the results of different sampling techinques. Classifiers such as Logistic Regression, Decision Tree, and XGBoost were applied. Models were evaluated using precision score. The code below fits different classifers and returns the scores for each model.
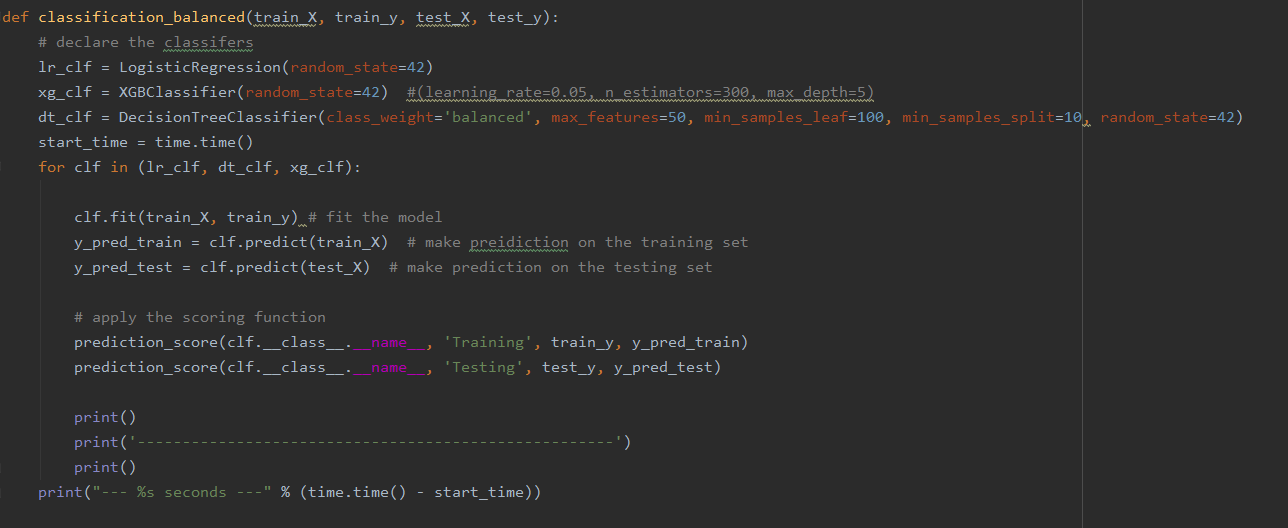
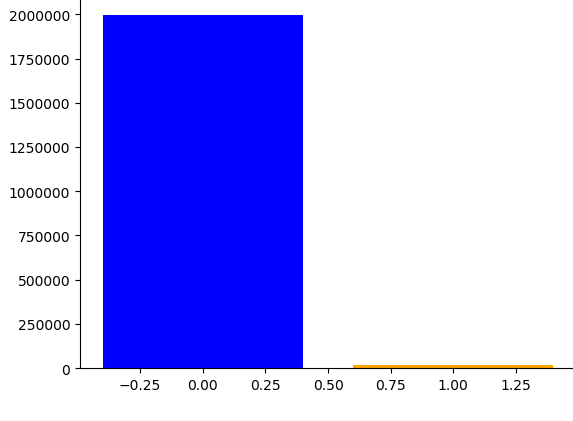
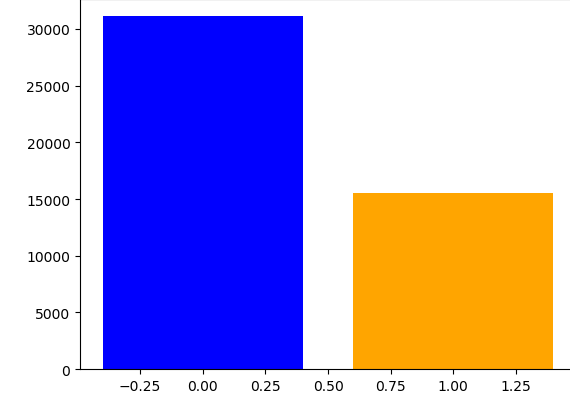
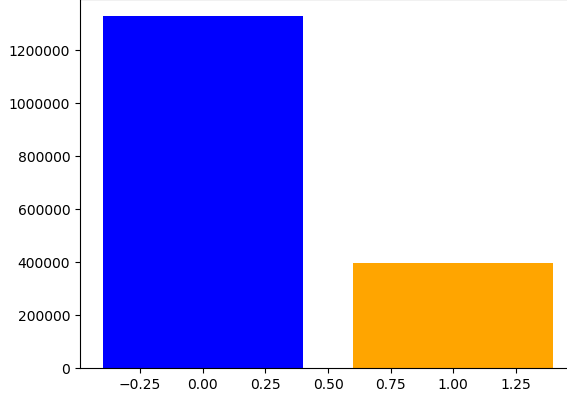
Figure 4 shows the class distributions of the original dataset and after resampling. The first plot shows the ditribution of the original dataset. Note that delinquency rate is only 0.77% of the entire population. The second plot shows the class distribution after undersampling the data by 50%. Samples from the majority class was removed so that the ratio of the two classes is 1:2. The third plot shows the data after applying both oversampling and undersampling. The minority class was increased by 20% from 20,000 in the original dataset to 40,000 in this dataset. Meanwhile, the majority class was decreased so that it is 30% more than the minority class.
1. Base Model - Full Population
The table below shows the scores after training on the entire population. Decision Tree overfitted in the training dataset. Precision score and F1 score of Logisic Regression is very high. This is because it failed to classify delinquency 100% of the time. If the evaluation criteria changes to identify loans that would later delinquent, this model would fail. Therefore, XGBoost on the full population is selected as the best model with the precision score of 0.829.
| Model | Precision Score Training | F1 Score Training | Precision Score Testing | F1 Score Testing |
|---|---|---|---|---|
| Logistic Regression | 0.996 | 0.498 | 0.992 | 0.996 |
| Decision Tree | 1.0 | 1.0 | 0.512 | 0.514 |
| XGBoost | 0.996 | 0.500 | 0.829 | 0.499 |
2. Undersampling 50%
The above plot shows the scores for training and testing sets after undersampling. Note that Decision Tree overfitted once again. XGBoost and Logistic Regression have the highest accuracy score. However, Logistic Regression has higher F1 score on the testing data. Overall, undersampling returned worse results than applying the classifiers on the entire population.
| Model | Precision Score Training | F1 Score Training | Precision Score Testing | F1 Score Testing |
|---|---|---|---|---|
| Logistic Regression | 0.752 | 0.735 | 0.515 | 0.497 |
| Decision Tree | 1.0 | 1.0 | 0.507 | 0.452 |
| XGBoost | 0.817 | 0.809 | 0.515 | 0.494 |
3. Combination
The table below shows the results after the data was oversampled by 20% and undersampled by 30%. On the testing set, XGBoost outperformed other models in both precision and F1 scores. The combination between oversampling and undersampling yeilded better results than just applying undersampling alone.
| Model | Precision Score Training | F1 Score Training | Precision Score Testing | F1 Score Testing |
|---|---|---|---|---|
| Logistic Regression | 0.747 | 0.695 | 0.521 | 0.524 |
| Decision Tree | 1.0 | 1.0 | 0.511 | 0.514 |
| XGBoost | 0.792 | 0.761 | 0.523 | 0.526 |
V. Conclusion
Through extensive analysis, this study:
- Identified the states with the most delinquency rate
- Profiled the characteristics of delinquent and performing loans
- Discovered the relationship between SATO and delinquent loans
- Experimented with different combinations of classifiers and resampling techniques